Did You Know?
Retrieval-Augmented Generation (RAG) has just received a significant upgrade. Ben Lorica’s latest piece outlines how forward-thinking teams are integrating agent-based planning, multimodal inputs, and end-to-end system tuning to move beyond the “pipeline of parts” mindset that characterized first-gen RAG. Highlights include:
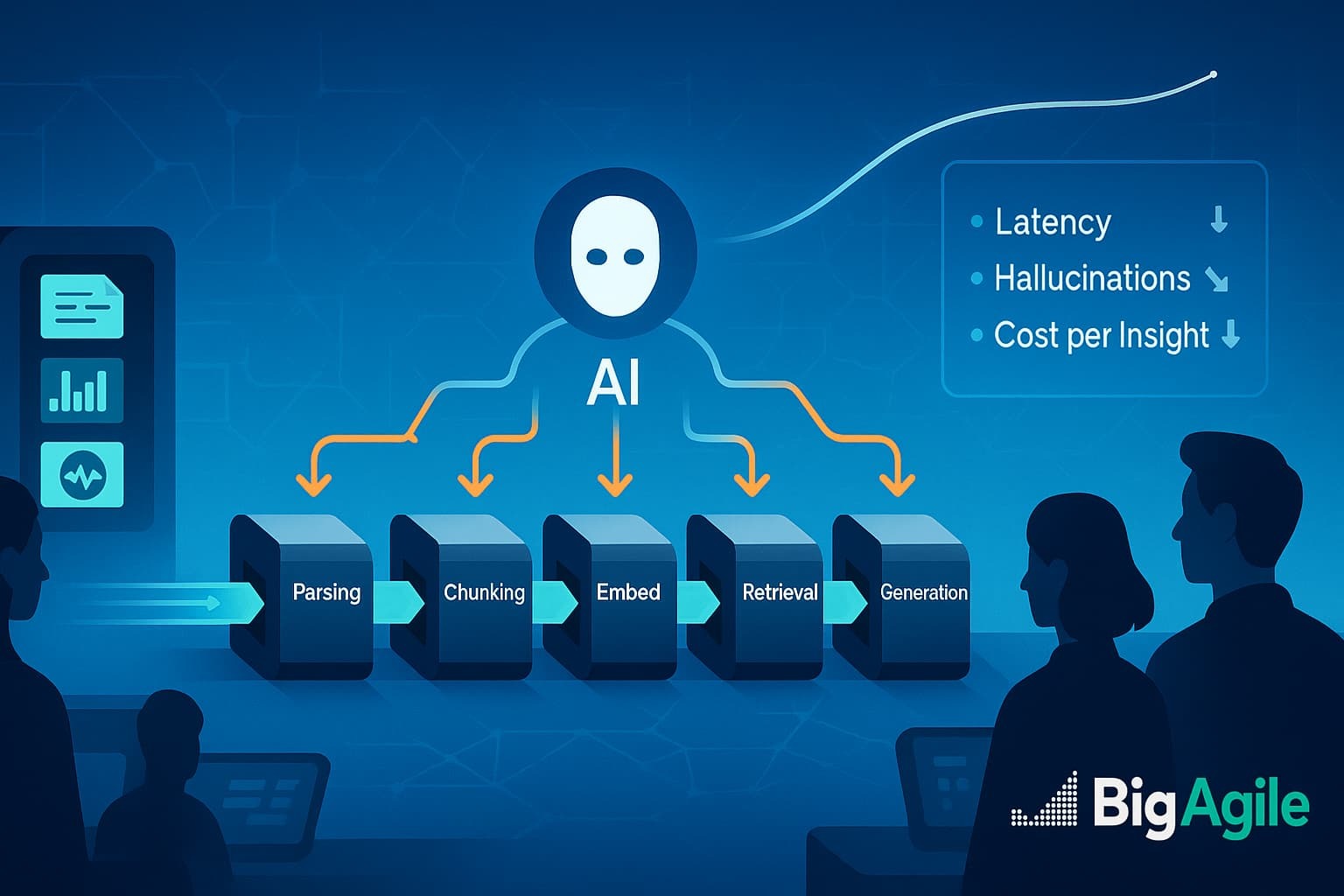
- System-optimized RAG 2.0: parsers, chunkers, embedding models, re-rankers, and LLMs are now co-engineered to prevent errors from snowballing downstream.
Built-in humility: “I-don’t-know” responses, citation enforcement, and post-generation verifiers are reducing the risk of hallucinations. - Agentic RAG: autonomous planners determine when (or if) to retrieve, chaining multi-step queries until the evidence is watertight.
- Multimodal reach: vision, speech, tables, and diagrams now exist in a unified index, powered by formats like Lance v2.
- RAG vs. long-context myth-busting: blindly stuffing million-token windows is wasteful; targeted retrieval still prevails in terms of accuracy and cloud expenditure.
So What?
For business leaders, this evolution reflects two timeless lessons:
- Whole-system thinking surpasses component tinkering. Reinertsen reminds us that queues; not task, dictate flow, cost of delay, and customer value. Similarly, RAG 2.0 enhances the interactions among AI components, rather than just optimizing the parts.
- Human-machine “superminds” amplify advantages. Malone’s research shows that the smartest outcomes emerge when diverse humans and AI collectively reason, share context, and self-correct. Agentic, multimodal RAG is the technical framework that allows those superminds to thrive.
- Trust is essential. Enterprises can’t afford hallucinated insights. Incorporating epistemic humility directly into AI workflows provides the psychological safety that boosts adoption, similar to Agile teams surfacing blockers early instead of hiding defects.
Now what?
Here’s how an executive team might act on these insights tomorrow morning:
- Map the knowledge flow from raw documents to decisions: include diagrams, spreadsheets, and voice recordings. Identify drop-offs where context or modality is lost.
- Pilot a “RAG readiness” spike: Start small: choose one product line, feed its documents into a multimodal vector store, and wrap an agent that can admit uncertainty. Track answer precision, latency, and compute cost.
- Introduce WIP limits for data ingestion: Just as kanban caps work-in-process, limit chunk sizes, embedding calls, and retrieval depth to curb queue bloat and keep latency predictable.
- Blend human checkpoints: Pair domain experts with the agent’s verifier step. This “human-in-the-loop” approach not only raises accuracy but also trains staff to ask better questions, boosting collective intelligence.
- Reframe success metrics: Move beyond raw model tokens. Measure cycle time from question to confident answer, grounded citation rate, and cost per valid insight.
Catalyst Leadership Questions
| Guiding Question | Probing Starter |
|---|---|
| Where does critical knowledge currently queue and decay? | “Which hand-offs slow decision-making the most this quarter?” |
| How might agentic RAG shrink those queues to minutes? | “If an AI planner retrieved *only* what mattered, what latency target feels game-changing?” |
| What “I don’t know” guardrails must be in place to earn stakeholder trust? | “When should our AI refuse to answer—and who adjudicates that?” |
| Which multimodal assets (images, CAD files, voice logs) are under-leveraged today? | “Where have teams manually copied data from visuals into text to make it ‘searchable’?” |
| How will we upskill teams to collaborate with AI superminds? | “What new roles, prompt engineer, verification analyst, fit our career ladder?” |
RAG’s second act isn’t a feature race; it’s a systems revolution. By combining flow-based thinking with collective-intelligence design, businesses can access exactly the right knowledge at the right moment, reduce cognitive WIP, and allow humans to focus on strategy rather than scavenger hunts.
Imagine it like Amazon Prime for insights: one-click, time-boxed, fully tracked delivery, minus the cardboard waste.