
Did you know…
OpenAI’s new o3 model just spotted a previously unknown use-after-free vulnerability (CVE-2025-37899) in the Linux kernel SMB server, without any customised framework, fuzzing harness, or symbolic execution. Security researcher Sean Heelan fed o3 roughly 12 kLoC of server-side C code and, in one of 100 runs, the model produced a concise human-style bug report that mapped the concurrent-session edge case, identified the risky free of sess->user, and reasoned about the race condition that could lead to remote code-execution in kernel context.
On an earlier 3.3 kLoC benchmark, o3 found another UAF eight times more often than Claude Sonnet 3.7 and never hallucinated a fix that merely NULLed the pointer, recognizing that other threads could still dereference the freed object.
Ok, so what?
- LLMs are now competitive with human code auditors for mid-sized modules. Earlier research showed GPT-4 could explain patches; o3 demonstrates that it can discover non-trivial concurrency bugs in <10 kLoC code bases, dramatically cutting analysts’ triage time.
- Cyber-risk profiles are shifting. If open-source kernels can be scanned this deeply by commodity AI, attackers will automate vulnerability hunting at scale. Boards will expect the same level of automated assurance from defenders — “AI for SecOps” moves from nice-to-have to baseline capability, much like static analysis did a decade ago.
- Talent leverage beats talent replacement. Heelan notes that o3 turns expert researchers into “10× auditors”, echoing MIT’s evidence that generative AI lifts the lower tail of performance and amplifies the top (see Module 5 Unit 1 on AI & Jobs). The machines aren’t replacing senior security engineers; they’re freeing them to focus on exploit weaponization modelling and coordinated disclosure strategy.
Now what?
Projects to try at home :)
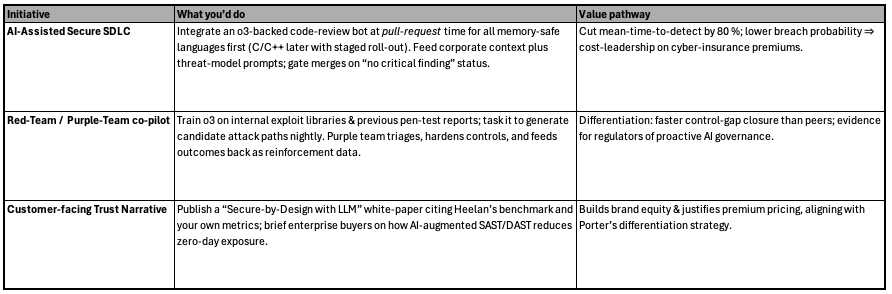
Questions to think about
- Signal-to-noise trade-off: Heelan still saw ~1 true positive per 50 runs. How will you resource human review without negating productivity gains?
- Context-window limits: Today’s 100 k-token windows miss deeper call chains. What architecture (chunking, retrieval-augmented prompts, proprietary short-listing heuristics) will you adopt to scale beyond 10 kLoC?
- Responsible disclosure & governance: If your AI finds an 0-day in an upstream dependency, what’s your policy for coordinated disclosure vs. immediate self-patch?
- Culture change: Kotter teaches that transformation stalls without a guiding coalition. Which security-engineering and DevOps leaders will champion AI-first code review, and how will you create early “short-term wins” to cement adoption?
- Competitive asymmetry: What happens when attackers pair o3 with autonomous exploit-chain generators — and your org does not?