Velocity, cycle time, and DORA provided us with clarity within a single squad. Let's step back to view the broader context of most implementations: ten squads, one product, one timeline. Dependencies, integration collisions, and “merge-hell” can disrupt even the most efficient pipelines. Below is a practical playbook that integrates with the Flow Radar stack you built this week.
1 Collect Cross-Team Events
This initial pull collects all open merge requests across every repository so you can identify dependencies before they merge into trunk. Centralizing data means you no longer have to search through six dashboards or ping ten developers for updates; everything you need is in one JSON file. Since you schedule this job nightly (or with every push), the data is always up-to-date, allowing you to run analytics without relying on tribal knowledge. Think of it as turning scattered repo chatter into a single source of truth.
Grab branch names, pull-request metadata, and dependency tags across every repo.
# GitLab API example (repeat for each group_id) curl -H "PRIVATE-TOKEN:${GITLAB_TOKEN}" \ "https://gitlab.com/api/v4/groups/456/merge_requests?state=opened" \ > group456_mrs.json
This will give you a single JSON dump of all in-flight work to spot impending collisions.
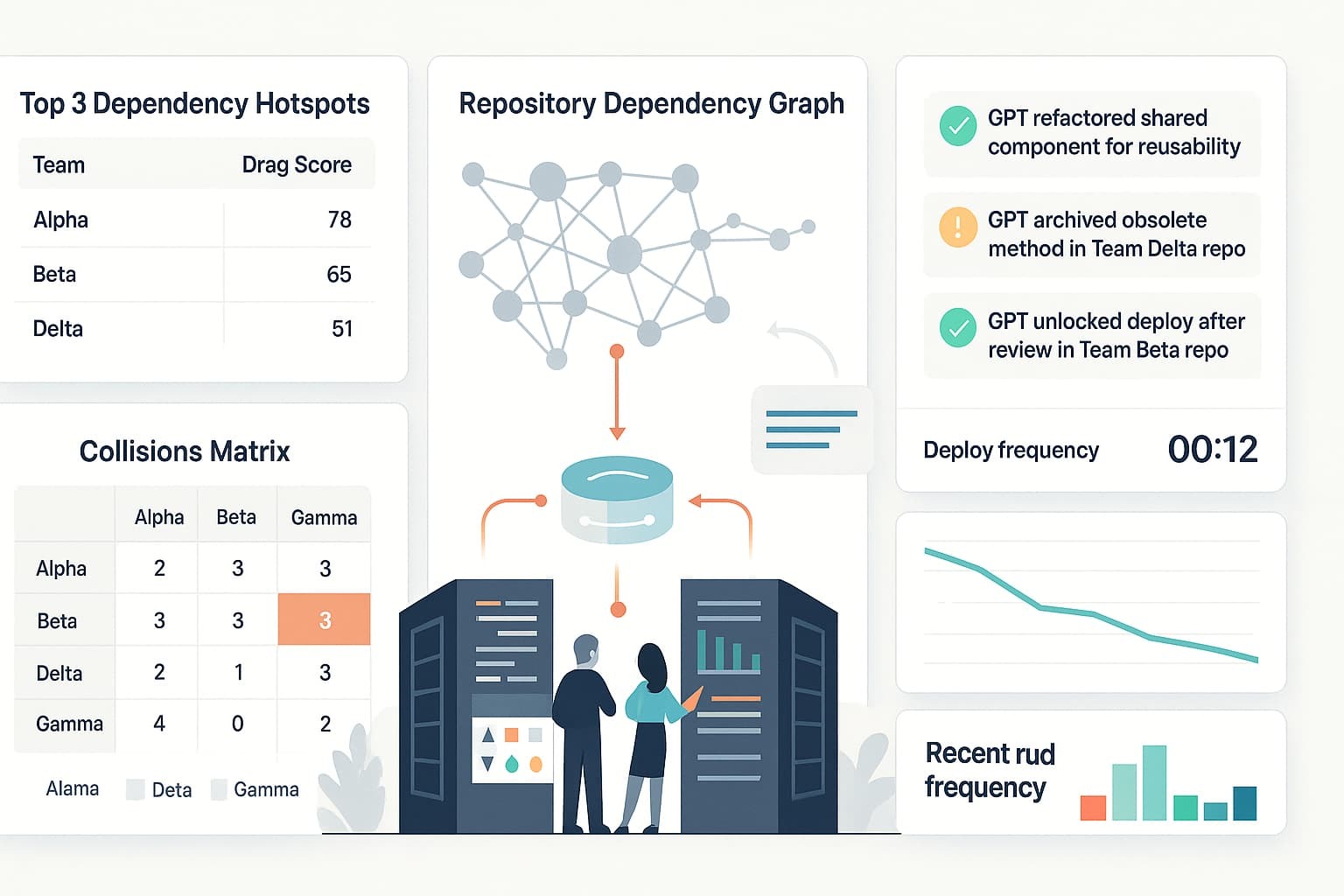
2 Detect Dependency Hotspots
By analyzing depends_on= labels and branch names, you identify the work items most likely to block downstream teams. Label-driven detection keeps the process simple—teams add a tag, and the radar lights up without the need for complex graph databases. The detailed list allows you to sort blockers by team, parent repo, or age, turning guesswork into a prioritized queue. Share the hotspot table in Slack so teams can proactively address the biggest bottlenecks.
Parse branch names (feature/login-service) and MR labels (depends_on=payments-api).
import pandas as pd, json, re mrs = pd.json_normalize(json.load(open('group456_mrs.json'))) mrs['depends_on'] = mrs['labels'].apply( lambda lbls: [l for l in lbls if l.startswith('depends_on=')]) hotspots = mrs.explode('depends_on').dropna(subset=['depends_on']) hotspots['parent'] = hotspots['depends_on'].str.replace('depends_on=', '')
Surfacing “parent” repos shows blockers before they ripple through downstream teams.
3 Flag Integration Collisions
Two branches touching the same files within 24 hours is a red flag for merge issues that could emerge. Tracking collisions at the file level highlights risky modules early, before CI alerts. This proactive check turns “surprise Friday merge hell” into a discussion on Wednesday about feature flags, branching strategies, or pairing. Over time, a decreasing collision list indicates healthier repo boundaries and better integration practices.
Look for two branches touching the same file set in the last 24 hours.
from collections import Counter file_buckets = Counter() for pr in hotspots['iid']: files = get_changed_files(pr) # call to Git provider bucket = tuple(sorted(files)) file_buckets[bucket] += 1 collision_candidates = [b for b, c in file_buckets.items() if c > 1]
This should serve as a collision waiting to break the build when two squads edit the same module simultaneously.
4 Generate the Multi-Team Radar Narrative
Raw tables are useful for engineers, but Scrum-of-Scrums reps need a clear agenda. Feeding hotspot and collision data into GPT turns numbers into a concise three-bullet summary everyone understands in 30 seconds. The LLM adds natural language, “Login-Service change blocks Payments-API”—so reps walk into the meeting already prepared to solve, not just report. Keep refining the prompt to match your organization’s tone and watch the SoS shift from status updates to a blocker-busting workshop.
Feed the hotspots and collisions to GPT so it writes a friendly SoS agenda.
prompt = f""" You are a Scrum-of-Scrums assistant. Hotspots: {hotspots[['project_id','parent','author','title']].to_json(orient='records')} Collisions: {collision_candidates[:5]} Return 3 bullet points: • biggest dependency blocker • highest-risk file collision • suggested next action """
Reps arrive at SoS with a prioritized agenda so that we can start the discussion off with the cross-team blockers.
5 Post Targeted Alerts
Broadcasting every alert to every channel causes fatigue. Pinging only the teams listed in a blocker keeps notifications actionable and respectful of attention spans. Naming the Slack channel #sos-alerts establishes a cultural norm: messages here are urgent and cross-team. Over a few sprints, teams learn that if their name appears, immediate coordination is required—no more “I didn’t see that” excuses.
Send Slack pings only to teams named in the hotspot list.
slack_msg = { "channel": "#sos-alerts", "text": "Flow Radar: top cross-team blockers", "blocks": [...] } requests.post(SLACK_URL, json=slack_msg)
6 Track Dependency Lead Time
Traditional lead-time ends at “code merged,” but cross-team work often remains in dependency limbo. Measuring the time from depends_on creation to clearance provides a KPI for SoS effectiveness. A downward trend confirms that your coordination meetings and automated nudges reduce waste. Publish the weekly average on the same dashboard as DORA metrics so leaders can see dependency drag decrease alongside cycle time and deploy frequency.
Create a new metric: time between “depends_on” created and cleared.
deps = hotspots.copy() deps['cleared_at'] = pd.to_datetime(deps['merged_at']) deps['dep_lead_time'] = (deps['cleared_at'] - deps['created_at']).dt.days trend = deps.groupby(deps['created_at'].dt.to_period('W'))['dep_lead_time'].mean()
Falling dependency lead time means your SoS is doing its job!
That's a Wrap!
Over four days, we turned static charts into a living Flow Radar:
- Day 1 flagged WIP age, blocked tags, and cycle-time outliers.
- Day 2 paired those alerts with Cycle-Time + PPC forecasting.
- Day 3 translated DORA metrics into board-ready narratives.
- Today we stitched ten squads together, exposing cross-team drag before it hits production.
You now own a pipeline that tells you where to look, what to fix, and how soon value ships. Keep the scripts on a nightly cadence, tune the prompts as goals evolve, and let AI handle the grunt work while your teams focus on solving real customer problems. Obviously each implementation will be slightly different, our developers are smart enough to figure out the details; I simply wanted to showcase a flow to mimic or make better. Flow Radar online, bottlenecks offline, time to ship.
Download the sample scripts, wire them into your backlog today (make them better BTW), and post your first cycle-time chart in Slack before tomorrow’s stand-up.
Then grab a seat in our AI for Scrum Master or AI for Product Owner micro-courses to turn those insights into automated coaching workflows.
Spots fill fast, hit the link, reserve your cohort, and show up with real data.