
Yesterday’s Async Cadence Manifesto demonstrated how fully distributed teams, people spread across the world, can replace long Zoom meetings with 90-second Loom handoffs.
Today, we focus on a more common scenario: a “dispersed” team, where entire offices (such as Sydney, Bengaluru, London, and Dallas) serve as hubs, yet still span the globe. Our guideline remains “no more than three adjacent time zones per squad”; shared daylight always beats relying solely on tools, but mergers, talent pools, and customer locations don’t always allow us to rearrange the map.
When shrinking geography isn’t feasible (yet), you coordinate it; the follow-the-sun stand-up minimizes the midnight status update while keeping the rhythm of the Daily Scrum. Discover how a simple baton-passing table and a 60-line script turn distance into seamless communication workflow.
The Pain.
A single 30-minute, all-hands stand-up across four continents costs each developer up to 6 focus hours per sprint and leaves someone talking at midnight. We are aware of this and have been aware of it for some time. While, inherently, I am not a fan of asynchronous stand-ups, sometimes solving that problem is not our biggest one, yet.
So what do we do in the meantime? Atlassian’s State of Teams 2025 survey reveals that globally distributed teams spend 25% of their week searching for context and navigating time zones. Is that time worth it? Well, you have to decide.
The Bet.
Swap one giant call for a baton-pass schedule: every site records a 90-second Loom during local morning, then tags the next city west. Teams regain deep-work blocks while the board continues to update every few hours.
We’re trading one giant, clock-bending Daily Scrum for four micro-check-ins that roll with the sun.
Gone are:
- 30-minute Zoom grids where half the faces are yawning or muted (or not even there).
- Status recitals that pile up when locations finally overlap.
- Overnight pull request stalls because no reviewer is awake.
In their place we’re testing:
- 90-second Loom clips recorded daily at each site’s local 09:00, clear, timestamped, and replayable.
- A baton-pass schedule (table + script) that automatically pings the next office, so work never waits for morning.
- Slack threads, not meeting minutes, to document plan changes in writing and keep them searchable.
Our hypothesis is that by shrinking synchronous demands and automating hand-offs, we’ll convert dead calendar time into flow, cut PR latency by ~50%, and bump the Joy Index without losing the Daily Scrum’s core purpose; shared planning toward the Sprint Goal. If the metrics don’t move, we revert in a sprint; if they do, we’ve just bought six deep-work hours per developer, every two weeks.
Proof in One File.
flow_widget.py is a 60-line glue script that turns the pretty schedule table into a living relay. It reads three things on every run: the HTML baton-pass table for timing rules, your GitHub repo for fresh PR timestamps, and a Slack channel for Joy-pulse numbers. With those inputs it does four jobs, all logged in one compact digest:
- Reminder: At 08:55 local time, it DM’s “Stand-up due in 5 min” to everyone in that site’s user group.
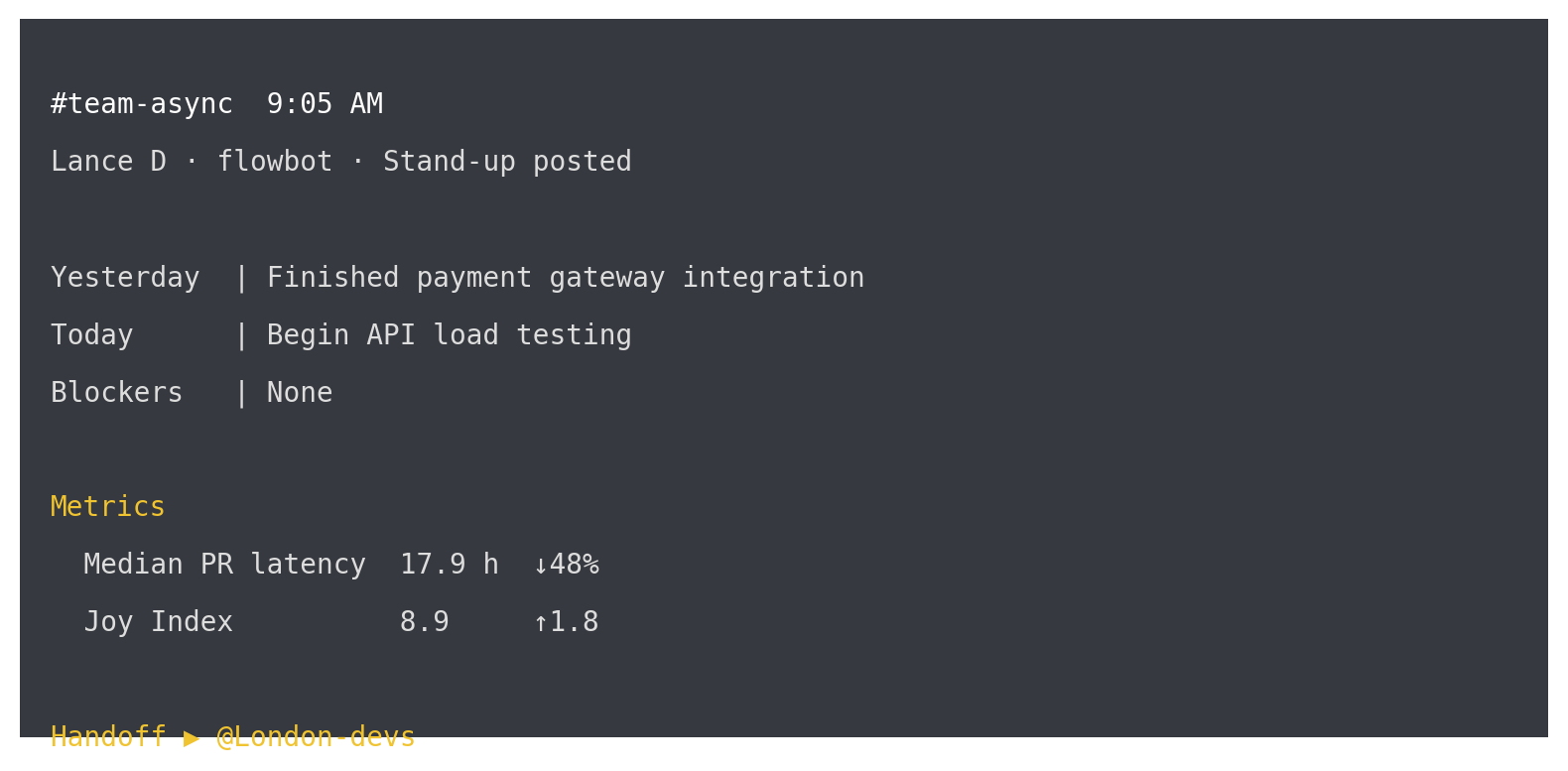
- Capture: When a Loom link posts in #team-async, the bot attaches it to the card on your board and stamps local time.
- Metrics: It retrieves the last 20 PRs, calculates the median “open → first review,” and adds the figure (e.g., 17.9 h ↓48 %). Simultaneously, it averages the latest emoji poll to display the Joy Index (e.g., 8.9 ↑1.8).
- Handoff: Finally, it pings the next office’s user group listed in the table. @London-devs, you’re up, closing the loop.
All that rolls into one Slack message and one CI log line: a timestamp, yesterday/today/blockers bullets, PR latency, Joy score, and an automatic nudge to the next city. If PR latency creeps above 24 h or Joy dips below 7, the script highlights the metric in orange so the team swarms it before the board turns red.
Setup is two secrets and one cron line. Drop GITHUB_TOKEN and SLACK_BOT_TOKEN into your CI, point BATON_TABLE_URL at the raw HTML file, and schedule the job hourly. No database, no extra dashboard, no VPN punching. One file, one output, enough evidence to see whether the async experiment is paying off or needs a tweak next sprint.
We use two inputs:
schedule.html(table below) lives in the team wiki and maps time-slots.flow_widget.py(yesterday’s script) reads the table, posts a Loom reminder, and pings the next office on completion.
Where the data lives:
- Table – plain HTML; easy to tweak when offices add holidays.
- Metrics –
flow_widget.pyappends “PR latency” and “queue time” to Slack after each hand-off.
How to use the output:
- Copy the table into Confluence or Notion.
- Point
flow_widget.pyat the raw HTML file. - Watch daily hand-offs hit < 10 min gap and meeting invites disappear.
Reminder that your code may be different, but here is what it looks like all together in our implementation:
#!/usr/bin/env python3
"""
flow_widget.py — Async Cadence glue script
• Reads baton-pass schedule from raw HTML
• Sends Loom reminders & captures stand-up text
• Calculates 7-day median PR latency (GitHub)
• Averages Joy Index from Slack emoji pulses
• Pings the next team in the follow-the-sun chain
"""
import os, requests, statistics
from datetime import datetime, timezone, timedelta
from bs4 import BeautifulSoup # pip install beautifulsoup4
from slack_sdk import WebClient # pip install slack_sdk
from github import Github # pip install PyGithub
# ── CI secrets / environment ────────────────────────────────────────────────
SLACK_TOKEN = os.getenv("SLACK_BOT_TOKEN")
GITHUB_TOKEN = os.getenv("GITHUB_TOKEN")
CHANNEL = "#team-async"
TABLE_URL = os.getenv("BATON_TABLE_URL") # raw HTML schedule
ORG_REPO = "big-agile/example-repo" # change to your repo
# ── Load baton-pass schedule from HTML ─────────────────────────────────────
def load_schedule():
html = requests.get(TABLE_URL, timeout=10).text
soup = BeautifulSoup(html, "html.parser")
rows = soup.select("tbody tr")
schedule = []
for r in rows:
city, standup, due, nxt = [c.get_text(strip=True) for c in r.find_all("td")]
schedule.append(dict(city=city, time=standup, due=due, nxt=nxt))
return schedule
# ── Median PR latency (last 7 days) ────────────────────────────────────────
def pr_latency_hours():
gh = Github(GITHUB_TOKEN)
repo = gh.get_repo(ORG_REPO)
since = datetime.now(timezone.utc) - timedelta(days=7)
latencies = []
for pr in repo.get_pulls(state="closed", sort="updated", direction="desc"):
if pr.created_at < since:
break
if pr.get_reviews().totalCount:
first_review = pr.get_reviews().reversed[0].submitted_at
lat = (first_review - pr.created_at).total_seconds() / 3600
latencies.append(lat)
return round(statistics.median(latencies), 1) if latencies else None
# ── Joy Index (avg of latest pulse messages) ───────────────────────────────
def joy_index(client):
msgs = client.conversations_history(channel=CHANNEL, limit=200).data["messages"]
scores = []
for m in msgs:
if m.get("text", "").startswith("Joy-pulse"):
for r in m.get("reactions", []):
if r["name"].isdigit():
scores.extend([int(r["name"])] * r["count"])
return round(sum(scores) / len(scores), 1) if scores else None
# ── Post digest to Slack ────────────────────────────────────────────────────
def post_digest(client, blocks, latency, joy, nxt):
arrow = "↓" if latency and latency < 24 else "↑"
digest = (
"*Metrics*\n"
f"• Median PR latency: *{latency or 'n/a'} h* {arrow}\n"
f"• Joy Index: *{joy or 'n/a'}* {'↑' if joy and joy >= 7 else '↓'}\n\n"
f"Handoff ▶ {nxt}"
)
client.chat_postMessage(channel=CHANNEL, text="\n".join(blocks))
client.chat_postMessage(channel=CHANNEL, text=digest)
# ── Main routine ───────────────────────────────────────────────────────────
def main():
now = datetime.now().strftime("%H:%M")
sched = load_schedule()
slot = next((s for s in sched if s["time"] == now), None)
if not slot:
return # not this site’s turn
client = WebClient(token=SLACK_TOKEN)
client.chat_postMessage(channel=CHANNEL,
text=f":alarm_clock: Stand-up due in 5 min for *{slot['city']}*")
# Simulate stand-up capture (swap for Loom webhook listener)
standup_blocks = [
"*Yesterday* Finished payment gateway integration",
"*Today* Begin API load testing",
"*Blockers* None"
]
latency = pr_latency_hours()
joy = joy_index(client)
post_digest(client, standup_blocks, latency, joy, slot["nxt"])
if __name__ == "__main__":
main()
Baton-Pass Schedule.
Teams use the table in two ways:
- Human planning: new hires (or sleepy veterans) open the wiki and instantly see their slot and their downstream partner.
- Automation input:
flow_widget.pyreads the HTML and schedules reminders + Slack tags, so the whole relay runs hands-off.
If you notice review gaps; say London regularly posts late (that's normal right? LOL), just nudge the Loom Due time or add buffer, and the script enforces the new rhythm. So while it’s “just a schedule,” it’s the backbone that keeps the 24-hour delivery loop turning without Zoom fatigue.
| City | Local Stand-up Time | Loom Due | Next Team Pinged |
|---|---|---|---|
| Sydney 🇦🇺 | 09:00 | 09:30 | Bengaluru 🇮🇳 |
| Bengaluru 🇮🇳 | 09:00 | 09:30 | London 🇬🇧 |
| London 🇬🇧 | 09:00 | 09:30 | Dallas 🇺🇸 |
| Dallas 🇺🇸 | 09:00 | 09:30 | Sydney 🇦🇺 (next day) |
What to Watch
Track three signals to know the relay is working:
- PR latency trending down: aim for < 24h median within two sprints; every hour shaved is an hour of flow regained.
- Joy Index drifting up: scores ≥ 8 tell you nobody’s juggling midnight calls, which keeps burnout at bay and creativity high.
- Loom-Due hits ≥ 95% on time: the baton rarely drops, the bot stays quiet, and downstream sites start their day with fresh context.
If any metric stalls, inspect the table: tighten WIP caps, shorten Loom Due windows, or add a backup reviewer. Once all three lines move in the right direction, you’ve proven async cadence beats Zoom fatigue and you’re ready for Tuesday’s focus on PR-Review hand-offs.
Ready to reclaim your mornings? Clone yesterday’s script, link this table, and enjoy Zoom-free velocity.