Most product teams have a delivery model. Very few have a learning model. That gap is what determines who adapts fast enough to matter in 2026.
Both models ship work. Both run sprints, hold reviews, and track metrics. But a delivery model optimizes for throughput. A learning model optimizes for evidence. In a market moving as fast as this one, evidence is the only durable advantage.
Gartner's 2026 strategic technology trends make this explicit: organizations that create durable value are the ones that drive responsible innovation and operational excellence together, not as a tradeoff. That requires a set of operating rituals that help teams learn at the pace the market demands.
This post lays out the five rituals that form a learning operating model, and a maturity path so you know where to start.
The five rituals of a learning operating model
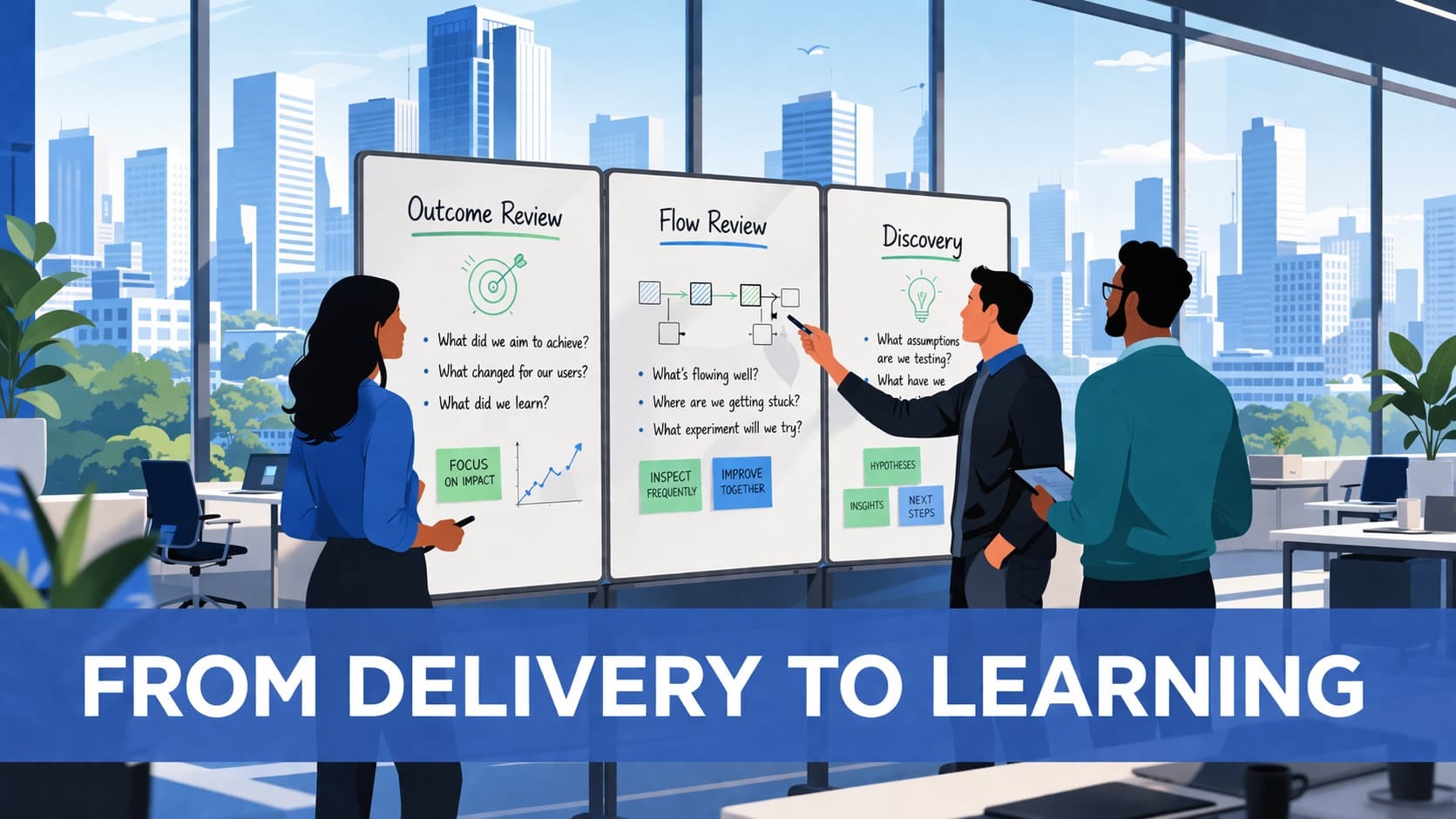
1. The Outcome Review
The Outcome Review is a weekly, timeboxed meeting with one purpose: did our bets change behavior, and what do we do next? It is not a status meeting. It is not a demo. It is not a retrospective. It is a decision meeting anchored to evidence.
The structure is simple. For each active bet, the team reviews one outcome metric (a behavior signal) and one delivery guardrail from the DORA four: deployment frequency, lead time for change, change failure rate, or time to restore. Then the team makes one clear call: double down, pivot, pause, or stop.
The right attendees are the Product Owner, Scrum Master, one or two developers, and anyone close to the customer signal (a customer success lead, a support rep, or a sales engineer who hears the feedback directly). Keep it tight. Under an hour. The goal is a decision, not a conversation.
2. The Flow Review
The Flow Review is a bi-weekly look at the system, not the work. Where is work piling up? Where is the constraint? Are the DORA guardrails trending in the right direction?
DORA 2024 is clear that high-performing teams are not the ones with the most capacity. They are the ones with the least waste between the moment a decision is made and the moment a user experiences the result. That waste lives in queues, handoffs, approval gates, and waiting time. The Flow Review is where you find it and name it, so you can start removing it.
The Flow Review should include the Product Owner, Scrum Master, Tech Lead, and an Engineering Manager or equivalent. The output is one concrete adjustment: a WIP limit change, a process simplification, or a decision to protect the constraint from new work until the queue clears.
3. The Discovery Cadence
Discovery is not a phase before delivery. In a learning operating model, discovery runs in parallel with delivery as a continuous habit. The job is to keep shrinking bets and shortening learning cycles so that what enters the sprint backlog is grounded in evidence, not assumptions.
A practical discovery cadence includes at least one customer conversation per week, one untested assumption identified per sprint, and one experiment running at any given time that could disconfirm the current roadmap direction. The anchoring question is always the same: what is the smallest version of this idea that would tell us whether we are right?
If the answer is consistently "we need six weeks," discovery is not happening. That is planning with extra steps.
4. Delivery Guardrails
Guardrails are the non-negotiable signals that tell you whether the system is healthy enough to keep learning from. You can chase outcomes aggressively and still do real damage if your change failure rate is climbing or your time to restore is degrading. Guardrails prevent that.
The DORA four metrics are a reliable starting set: deployment frequency tells you how often you are delivering learning opportunities to users; lead time for change tells you how quickly decisions become experiences; change failure rate tells you whether you are staying stable while moving fast; and time to restore tells you how well you recover when something breaks. Together they give you a system view. Watching only one of them gives you a number that can be optimized for in ways that harm the others.
The practical rule is straightforward: if any guardrail trends the wrong direction for two consecutive reviews, slow down the pace of change and fix the system before adding new bets. Speed without stability is not learning. It is noise.
5. Lightweight Governance
Governance gets a bad reputation because most organizations implement it as a committee that slows things down. Lightweight governance is the opposite: standing decisions that remove the need for repeated approvals and enable faster movement with appropriate oversight.
In 2026, this matters especially for AI. Gartner identifies AI-native development platforms and digital provenance as strategic imperatives: the ability to verify where AI outputs came from and whether they can be trusted is no longer optional. Governance done well answers "who is accountable for this output and what happens if it is wrong" before the question needs to be asked under pressure.
A lightweight governance model has three layers: a risk tier for each AI-assisted workflow (low, medium, high), a proportional human review requirement matched to that tier, and a regular cadence to revisit the tiers as the work evolves. No steering committee. No approval queue. Just clear standing agreements that let teams move and stay accountable simultaneously.
Three maturity levels
Most teams do not adopt all five rituals at once. Here is a realistic maturity path that shows where to start and what to add as the team builds capacity.
Level 1: Delivery with basic feedback loops
The team ships consistently but reviews outcomes anecdotally. Outcomes are often defined after the fact. Discovery is informal. DORA metrics may be tracked but not acted on in a structured way. Governance is handled case by case.
The single best move from Level 1: run your first Outcome Review. Block 45 minutes after your next sprint review, gather the Product Owner and two people closest to the user signal, and ask "what behavior changed this sprint?" Whatever answer you get is your starting point.
Level 2: Structured learning with regular cadence
Weekly Outcome Reviews run with defined outcome metrics and active bets. The Flow Review is bi-weekly with DORA guardrails on a simple run chart. Discovery conversations happen at least once per week. AI tools have a documented risk tier. Learning is becoming a habit rather than a one-time event.
The signal that a team has reached Level 2: someone can answer without looking anything up what the current session action rate or lead time baseline is, and what changed since the last review.
Level 3: Learning organization with compounding advantage
All five rituals run consistently. Outcomes are defined in behavior language before sprint planning begins. Bets are resolved on evidence, not calendar. Flow is managed proactively. Governance is clear, light, and updated regularly. The team can tell you how many bets they resolved last quarter and what the next assumption they are testing is.
Level 3 is not a destination. It is a practice. The teams I see sustaining it are not doing more. They are doing the same five things with increasing precision, and the compound effect of faster learning cycles shows up in outcomes over time.
Do this Monday morning
Pick one team. Pull up their last sprint. Ask one question: what did users do differently as a result of what we shipped? Write down the answer, or the silence. That is your Level 1 Outcome Review.
If you want to go further, run the Q2 Reset Worksheet from Tuesday's premium newsletter with your team this week. It walks through all five sections: outcomes, constraints, learning bets, measures, and cadence. Thirty minutes solo or ninety minutes with your team.
The operating model is not complicated. The rituals are not expensive. What they require is a decision to stop measuring motion and start measuring learning. Make that decision this week, before Q2 gets away from you.